
Search Engines Kaise Kam Karte Hai : यदि आप Designer, Developer, Small Business Owner या Marketing Professional हैं, तो आपको यह सीखना चाहिए कि Search Engines कैसे काम करते हैं।
Search कैसे काम करता है, इसकी स्पष्ट समझ अगर आप में है, तो यह आपको एक ऐसी वेबसाइट बनाने में मदद कर सकती है जिसे Search Engines पूरी तरह से Access, Index और Rank कर सकें, जिसके कई Benefits हैं।
यह पहला कदम है जिसे आपको Search Engine Optimization (SEO) या किसी अन्य SEM (Search Engine Marketing) कार्यों से निपटने से पहले उठाना होगा।
इस Post में आप सीखेंगे कि Users को जानकारी खोजने, व्यवस्थित करने और प्रस्तुत करने के लिए Search Engines कैसे काम करते हैं।
Search Engine क्या है?
Search Engine एक Complex Software System है, जो Web पर खोज करके ऐसे Web Pages ढूंढता है जो Users की Search Query का जवाब देते हैं।
खोज परिणाम (SERPs) Users जो खोज रहा है, उसके Importance और Relevance के क्रम में प्रस्तुत किए जाते हैं।
Modern Search Engines अपने परिणामों में विभिन्न प्रकार के Content शामिल करते हैं, जिनमें Articles, Images, Videos, Social Media Post और Forum Postings शामिल हैं।
सबसे Popular Search Engine Google है, जिसकी Internet पर हिस्सेदारी 90% से अधिक है। इसके बाद Bing, DuckDuckGo और अन्य का स्थान आता है।
Search Engines Kaise Kam Karte Hai

Search Engines उनके Web Crawlers का उपयोग करके सार्वजनिक रूप से उपलब्ध Pages को Crawl करके काम करते हैं।
Web Crawlers (Spiders या Bots) विशेष Programs होते हैं, जो नए Pages या Updated Content खोजने के लिए Web को Crawl करते हैं और इस जानकारी को Search Index में Add करते हैं।
यह प्रक्रिया तीन Main Stages में विभाजित है:
- पहला Stage – जानकारी की खोजने की प्रक्रिया है।
- दूसरा Stage – Information को Organize करना है।
- तीसरा Stage – यह तय करना है कि Search Query के परिणामों में कौन से Pages दिखाए जाएं और किस क्रम में दिखाए जाएं।
इसे आम तौर पर Crawling, Indexing और Ranking के रूप में जाना जाता है।
1. Crawling
Crawling प्रक्रिया के दौरान Search Engines का लक्ष्य Internet पर सार्वजनिक रूप से उपलब्ध जानकारी को खोजना होता है। इसमें नए Content या मौजूदा Content में किए गए Update शामिल हैं। वे Crawlers नामक कई Software Programs का उपयोग करके ऐसा करते हैं।
एक Complicated Process को सरल बनाने के लिए, आपके लिए यह जानना जरूरी है कि Crawler का काम Internet को Scan करना और Websites को Host करने वाले Servers (Web Servers) को ढूंढना है।
Crawler सभी Web Servers और प्रत्येक Server द्वारा Host की गई Websites की List बनाते हैं।
Crawler प्रत्येक Website पर जाते हैं और विभिन्न Techniques का उपयोग करके यह पता लगाते हैं कि उनमें कितने Pages हैं और प्रत्येक Page पर Content का प्रकार क्या है।
किसी Web Page पर जाते समय, वे अधिक से अधिक Pages को खोजने के लिए किसी भी Link (Internal या External) को Follow करते हैं।
वे ऐसा लगातार करते हैं और वेबसाइट में किए गए परिवर्तनों पर नज़र रखते हैं, ताकि उन्हें पता रहे कि कब नए Pages जोड़े या हटाए गए, कब Links Update किए गए हैं।
यदि आप इस बात पर विचार करें कि आज Internet पर 130 Trillion से अधिक Individual Pages हैं, तो आप कल्पना कर सकते हैं कि यह कितना बड़ा काम है।
Crawling Process की Value क्यों करें?
Search Engines के लिए Website को Optimize करते समय आपको पहले यह सुनिश्चित करना है कि वे इसे सही ढंग से Access कर सकें। अगर वे आपकी Website को Read नहीं कर सकते हैं, तो आपको High Ranking या Search Engine Traffic के संदर्भ में ज्यादा उम्मीद नहीं करनी चाहिए।
जैसा कि अभी आपने पढ़ा, Crawlers के पास करने के लिए बहुत सारा काम होता है और आपको उनका काम आसान बनाने का प्रयास करना चाहिए।
यह सुनिश्चित करने के लिए कई चीजें हैं कि Crawlers बिना किसी समस्या के सबसे तेज तरीके से आपकी Website को Search और Access कर सकें।
Robots.txt का उपयोग करके यह Specify करें कि आपकी Website के कौन से Page पर आप Crawler को Access नहीं देना चाहते हैं।
Google और Bing जैसे बड़े Search Engines के पास ऐसे Tools (Webmaster Tools) होते हैं, जिनका उपयोग करके आप उन्हें अपनी Website के बारे में अधिक जानकारी दे सकते हैं, ताकि उन्हें इसे Self Search करने की आवश्यकता न पड़े।
अपनी Website के सभी Important Pages को List करने के लिए XML Sitemap का उपयोग करें, ताकि Crawlers यह जान सकें कि Changes के लिए किन Pages पर नज़र रखनी है।
Search Engine Crawlers को किसी Particular Page को Index न करने का निर्देश देने के लिए “Noindex” Tag का उपयोग करें।
अधिक जानकारी के लिए आप Technical SEO पोस्ट को पढ़ें, ताकि आप सही से जान सकें।
2. Indexing
Search Engine बनाने के लिए सिर्फ Crawling ही काफ़ी नहीं है। Crawlers द्वारा पहचानी गई जानकारी को Organize, Sort और Store किया जाना चाहिए, ताकि Search Engine Algorithms इसे Users को उपलब्ध कराने से पहले Process कर सकें। इस Process को Indexing कहा जाता है।
Search Engines किसी Page पर पाई जाने वाली सभी जानकारी को Store नहीं करते हैं, लेकिन वे कुछ चीजें रखते हैं, जैसे कि वह कब Created या Updated किया गया है, Page Title और Description, Content का प्रकार, संबंधित Keywords, Incoming और Outgoing Link तथा कई अन्य Parameters, जो उनके Algorithms के लिए आवश्यक हैं।
Google अपने Index को एक बहुत बड़ी किताब के पिछले हिस्से के रूप में Describe करना पसंद करता है।
Indexing Process की Value क्यों करें?
यह बहुत सरल है, यदि आपकी Website उनके Index में नहीं है, तो यह किसी भी Search में दिखाई नहीं देगी।
इसका यह भी अर्थ है कि Search Engine Indexes में आपके जितने अधिक Pages होंगे, उतना ही किसी के द्वारा Question Type करने पर आपकी Search Results में आने की संभावना अधिक होगी।
ध्यान दें कि यहाँ ‘Search Results में दिखाई देना’ शब्द का उल्लेख किया है, जिसका अर्थ है किसी भी स्थिति में दिखाई देना, जरूरी नहीं कि वह Top Positions या First Page पर ही हो।
SERPs (Search Engine Results Pages) के पहले 5 Positions पर प्रदर्शित होने के लिए, आपको Search Engine Optimization (SEO) Process का उपयोग करके अपनी Website को Search Engines के लिए Optimize करना होगा।
कैसे पता करें कि Website के कितने Pages Google Index में शामिल हैं?
आपकी Website Google में Index है या नहीं, यह पता करने के दो तरीके हैं।
Google Open करें और Site Operator के बाद अपने Domain नाम का उपयोग करें। उदाहरण के लिए:
Site:absehindi.in
इससे आपको पता चल जाएगा कि किसी विशेष Domain से संबंधित कितने Pages Google Index में शामिल हैं।
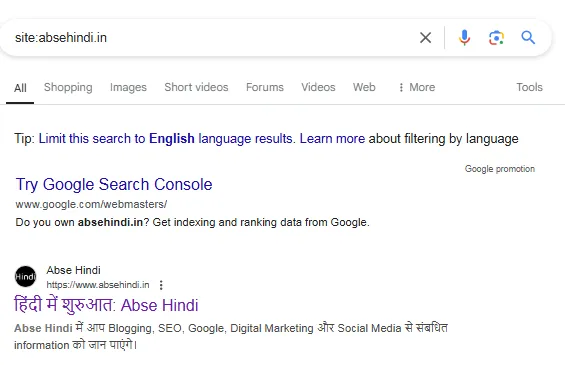
दूसरा तरीका यह है कि आप एक Google Search Console Account बनाएं और उसमें अपनी Website Add करें। फिर Indexing > Pages के अंतर्गत स्थित Indexed Pages Report देखें।
3. Ranking
प्रक्रिया का अंतिम Stage Search Engines के लिए यह तय करना है कि SERPs में कौन से Pages दिखाए जाएं और जब कोई व्यक्ति कोई Query Type करे, तो उसे किस क्रम में दिखाया जाए।
इसे Ranking प्रक्रिया कहा जाता है और इसे Search Engine Ranking Algorithms के उपयोग के माध्यम से प्राप्त किया जाता है।
सरल शब्दों में कहें, तो ये Software के ऐसे हिस्से हैं जो कई नियमों का उपयोग करके यह तय करते हैं कि किसी Search Query के लिए कौन से परिणाम Best होंगे।
ये Rules और Decisions उनके Index में उपलब्ध जानकारी के आधार पर बनाए जाते हैं।
Search Engine Algorithms कैसे काम करते हैं?
Search Engine Algorithms सभी Internet Users की Queries के लिए सबसे अच्छा Match Content खोजने के लिए कई Factors और Signals की जांच करते हैं।
इसमें Users द्वारा Type किए गए शब्दों के लिए Relevant Content, Page की उपयोगिता, Users का Location, अन्य Users को Particular Query के लिए क्या उपयोगी लगा और उसके अलावा कई Factors शामिल हैं।
यह Mention करना Important है कि पिछले कुछ वर्षों में Search Engine Ranking Algorithms वास्तव में जटिल हो गए हैं। आज से 20–25 साल पहले ये Users की Queries को Page के Title से Match करके Results दिखा देते थे, लेकिन अब ऐसा नहीं है।
Google का Ranking Algorithms कोई निर्णय लेने से पहले उसके 255 से अधिक नियमों पर विचार करता है, लेकिन कोई भी निश्चित रूप से नहीं जानता कि ये नियम क्या हैं।
Search Engines सभी Web Pages पर मौजूद Content की सीमाओं के अंदर और बाहर के Parameters के आधार पर निर्णय लेने के लिए Machine Learning और AI का उपयोग करते हैं।
इसे समझना आसान बनाने के लिए, यहाँ Search Engine Ranking Factors कैसे काम करते हैं, इसकी एक सरल Process दी गई है:
Step 1: User की Query का विश्लेषण करें
Search Engines के लिए पहला कदम यह समझना है कि Users किस प्रकार की Information Search कर रहा है।
ऐसा करने के लिए वे User की Query (यानि Search Term) को कई Meaningful Keywords में विभाजित करके उसका विश्लेषण करते हैं।
Keyword एक ऐसा शब्द है जिसका एक Specific Purpose और Meaning होता है।
उदाहरण के लिए, जब आप “User-Friendly Theme कैसे बनाएं” Type करते हैं, तो Search Engine को “कैसे करें” शब्दों से पता चल जाता है कि आप User-Friendly Theme बनाने के Instructions की तलाश कर रहे हैं और इस प्रकार Results में Themes बनाने वाली Websites की List मिल जाती है।
यदि आप “Buy Refurbished Products” खोजते हैं, तो वे Buy और Refurbished शब्दों से जान जाते हैं कि आप कुछ खरीदना चाहते हैं और Results में E-Commerce Website की List आ जाती है।
Machine Learning ने उन्हें संबंधित Keywords को एक साथ जोड़ने में मदद की है। उदाहरण के लिए, वे जानते हैं कि “WordPress में Theme कैसे Change करें” Query का अर्थ इसी तरह के सवाल से मेल खाता है।
वे Spelling Mistakes, Plural Words तथा Natural Languages (Written या Voice Search) से प्रश्न का अर्थ निकालने में भी काफी Smart होते हैं।
Step 2: Matching Pages को ढूंढना
दूसरे Step में उनके Index को देखना और यह तय करना होता है कि कौन से Pages किसी Question का Best Answer दे सकते हैं।
यह Search Engines और Webmasters दोनों के लिए पूरी प्रक्रिया में एक बहुत ही Important Step है।
Search Engine को Fastest Possible Way से Result देने की आवश्यकता होती है, ताकि वे अपने Users को खुश रख सकें। Webmasters चाहते हैं कि उनकी Website को चुना जाए, ताकि उन्हें Traffic और Visits मिलें।
यह वह Step भी है जहाँ अच्छी SEO Techniques Algorithms द्वारा लिए गए Decisions को प्रभावित कर सकती हैं।
Matching को समझने के लिए यहाँ कुछ Important Factors दिए गए हैं:
Title और Content Relevance: Page का Title और Content User की Query के लिए कितना Relevant है।
Content का प्रकार: यदि Users Images के लिए पूछता है, तो Results में Text नहीं बल्कि Images दिखाई जाएंगी।
Content की Quality: Content संपूर्ण, Useful, Informative, Unbiased और विषय के सभी पहलुओं को Cover करना चाहिए।
Website की Quality: Website की Overall Quality मायने रखती है। Google उन Websites के Pages नहीं दिखाएगा जो उसके Quality Standards को पूरा नहीं करते हैं।
Publication Date: News से संबंधित प्रश्नों के लिए Google Latest Results दिखाना चाहता है, इसलिए Publication Date पर भी विचार किया जाता है।
Page की Popularity: यह इस बात से जुड़ा है कि दूसरी Websites उस Page को कैसे देखती हैं। जिस Page पर दूसरी Websites से अधिक References (Backlinks) होते हैं, वह ज्यादा Popular माना जाता है।
Page की भाषा: Users को Pages उनकी भाषा में दिखाए जाते हैं, यानी Content ढूंढने के लिए सिर्फ English पर निर्भर नहीं रहना होता।
Web Page Speed: Website की Loading Speed अच्छी होनी चाहिए। Page लगभग 2–3 Second में Load हो जाना चाहिए।
Device का प्रकार: Mobile पर Search करने वाले Users को Mobile-Friendly Pages दिखाए जाते हैं।
Location: Users को उनके Area से संबंधित Results दिखाए जाते हैं।
जैसा कि पहले बताया गया है, Google अपने Algorithms में 255 से ज़्यादा Factors का उपयोग करता है, ताकि यह सुनिश्चित किया जा सके कि उसके Users अपने Results से खुश रहें।
Step 3: Users के समक्ष Results प्रस्तुत करना
Search Results, जिन्हें आमतौर पर Search Engine Results Pages (SERPs) कहा जाता है, एक Ordered List में प्रस्तुत किए जाते हैं।
SERPs के Layout में अक्सर विभिन्न Elements शामिल होते हैं, जैसे Organic Listings, Featured Snippets, People Also Asked, People Also Search, Paid Advertisements, Rich Snippets, Knowledge Graphs और बहुत कुछ, जो Query की प्रकृति पर निर्भर करता है।
उदाहरण के लिए, किसी Specific News की खोज करने पर हाल के News Articles दिखाई दे सकते हैं, जबकि किसी Local Food Court की खोज करने पर आसपास के स्थानों वाला Map प्रदर्शित हो सकता है।
Search Engine Ranking Algorithms की Value क्यों करें?
Search Engine से Traffic प्राप्त करने के लिए आपकी Website का Results के First Page पर Top Positions पर दिखाई देना बहुत जरूरी है।
यह Statistically Proven है कि ज्यादातर Users हमेशा Top 5 Results (Mobile और Desktop दोनों) में से किसी एक पर Click करते हैं।
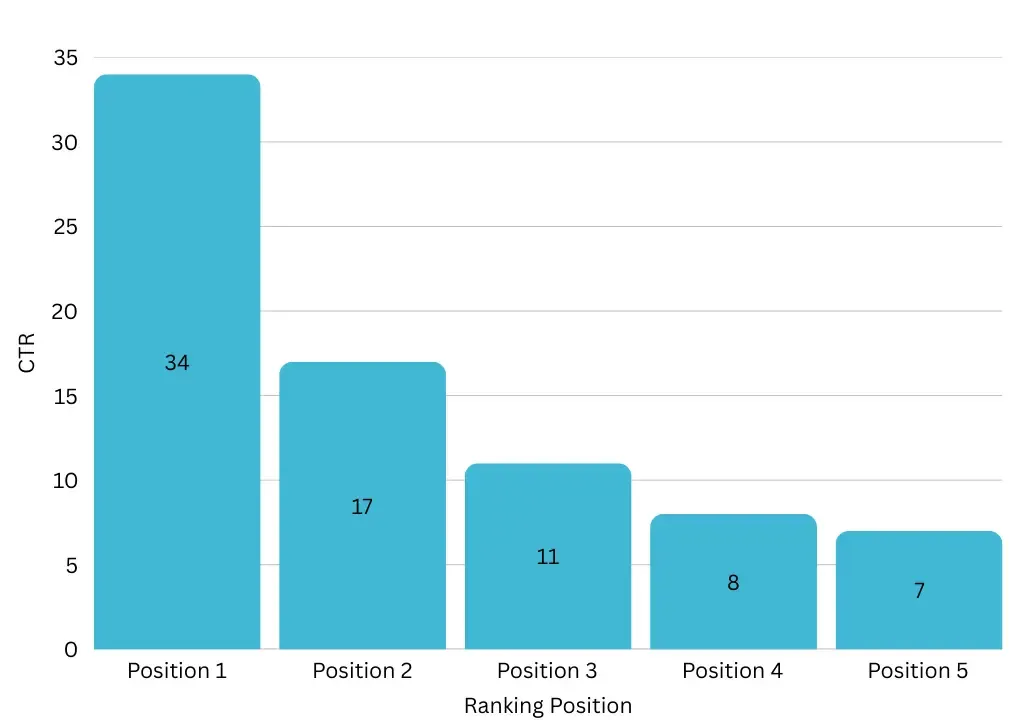
Results के दूसरे या तीसरे Page पर प्रदर्शित होने से आपको लगभग कोई Traffic नहीं मिलता।
अगर आप Search Engines कैसे काम करते हैं, यह अच्छी तरह समझ जाते हैं, तो Website को Adjust करने, Ranking सुधारने और Traffic बढ़ाने में मदद मिल सकती है।
आखिर में
Search Engines बहुत जटिल Computer Programs बन गए हैं। उनका Interface सरल हो सकता है, लेकिन जिस तरह से वे काम करते हैं और निर्णय लेते हैं, वह काफ़ी कठिन है।
यह प्रक्रिया Crawling और Indexing से शुरू होती है। इस Phase के दौरान Search Engine Crawlers Internet पर उपलब्ध Websites से अधिक से अधिक Information Collect करते हैं।
वे इस Information को खोजते हैं, Sort करते हैं और ऐसे Format में Store करते हैं, जिससे Search Engine Algorithms निर्णय ले सकें और Users को Best Possible Results लौटाए जा सकें।
उन्हें बहुत ज़्यादा Data Store करना पड़ता है और यह पूरी प्रक्रिया पूरी तरह Automated होती है। Human Intervention केवल Algorithms के नियम Design करने की Process में होता है, लेकिन यह भी धीरे-धीरे Artificial Intelligence की मदद से Replace किया जा रहा है।
एक Webmaster के रूप में आपका काम Simple और Straightforward Structure वाली Website बनाकर उनके Crawling और Indexing कार्य को आसान बनाना है।
जब वे बिना किसी समस्या के आपकी Website को Read कर पाते हैं, तो आपको यह सुनिश्चित करना होता है कि आप उन्हें उनकी Search Ranking Algorithms में मदद करने के लिए सही Signals दें और जब कोई User कोई Relevant Query Type करे, तो वह सीधा आपकी Website को चुने, इसी को SEO कहते हैं।
उम्मीद करता हूँ कि इस Post में आपको Search Engines के काम करने के तरीके के बारे में अच्छी जानकारी मिली होगी। Blogging की शुरुआत इन सारी Information को समझकर ही सही तरीके से की जा सकती है।








Mahi
Hello friends! My name is Mahi and I am the Founder & Writer of ABSEHINDI.IN. I write content related to Blogging, Technology, Make Money, and Education. Hope you like my articles!
Organic CTR Kya Hai और इसे Increase करने के 6 तरीके
Organic CTR Kya Hai : यहाँ आप जानेंगे कि Organic CTR क्या है, यह क्यों मायने रखता है…
Read MoreOrganic Traffic Kya Hai | Organic Traffic क्या है – 4 तरीकों से इसे Increase करे
Organic Traffic Kya Hai : इस पोस्ट में, आप सीखेंगे कि Organic Traffic क्या है? Organic Traffic आपकी…
Read MoreAdSense Account Safe Kaise Rakhe | Google AdSense Account को Safe कैसे रखे
AdSense Account Safe Kaise Rakhe : Google AdSense Account को Safe कैसे रखे? यह सवाल उन सभी Bloggers…
Read MoreGoogle Adsense Kya Hai | Google AdSense क्या है और कैसे काम करता है – पुरी जानकारी
Google Adsense Kya Hai और यह कैसे काम करता है? अगर यह सवाल आपके दिमाग में बार-बार आ…
Read More